= 大模型+ memory + planning + tools (或者加上与环境交互的能力)变得能像人一样在实践中根据信息修改计划与行为
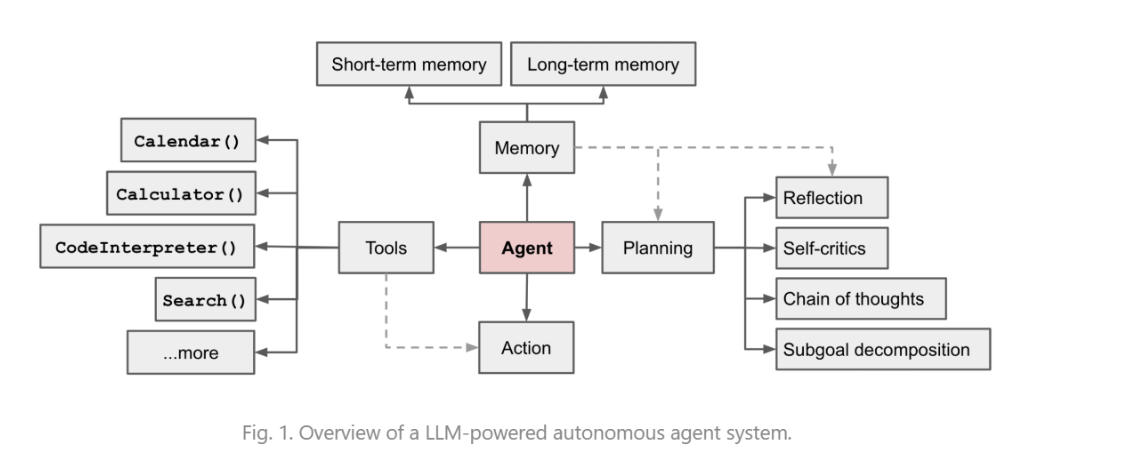
Plan#
子目标分解
CoT chain of thoughts
ToT Tree of thoughts
LLM + P PDDL标准化的通用领域规划语言,描述可行动作、初始状态和目标状态的语言,帮助规划器生成计划。通常用于ai的自动规划问题
自我反思
ReAct:
通过思考、行为、观察的多次循环提高答案的准确性
Reflexion
强化学习框架,结合了强化学习和自我反思的概念,从成功的学习中学习,并从失败中获得反馈,改进未来的策略
通过简单的二元奖励,动作空间与REAct类似的设置,在每个动作后,agents都会通过启发函数计算出一个启发值,决定是否重置环境或继续执行任务
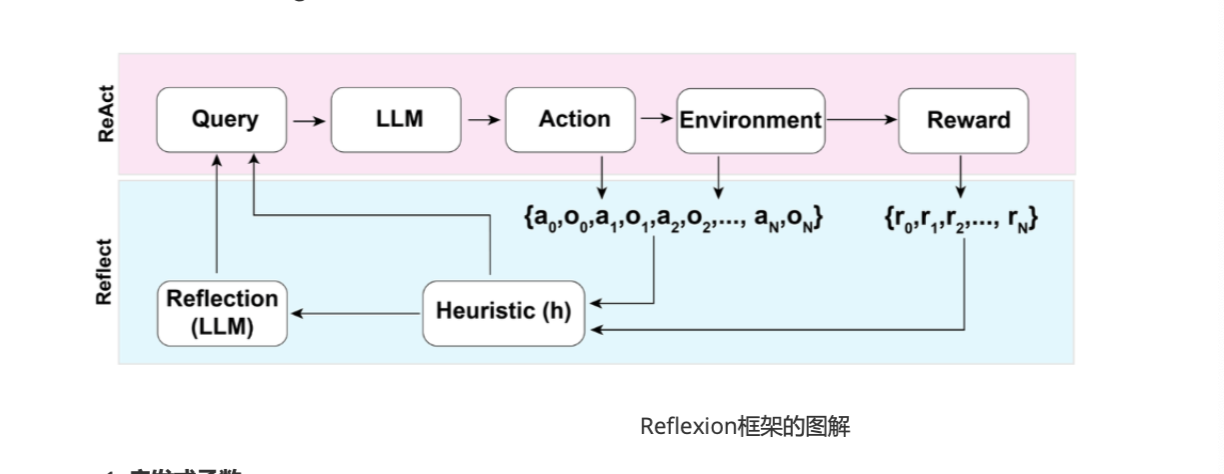 启发式函数:帮助agent判断某个轨迹(即一系列行动)是否低效或存在幻觉,如果是,则停止该轨迹并重新开始
启发式函数:帮助agent判断某个轨迹(即一系列行动)是否低效或存在幻觉,如果是,则停止该轨迹并重新开始
- 低效规划:采取行动过于缓慢或没有带来实际进展,尽管进行了很多步骤
- 幻觉:重复做相同的动作而这些动作并未产生新的观察或变化,导致Agent进入了死循环
自我反思:
- 两步示例:失败示例、理想反思
- 这些反思会加入到短时记忆中,最多存储三个反思。短期记忆允许agent在执行任务时引用这些反思,以帮助其做出更好的决策
Chain of Hindsight
利用自我反思改进模型输出的训练方法, 让模型能够给予过去的输出和反馈生成更高质量的结果,通过 人类反馈数据 和 历史输出序列 来进行模型的微调
人类反馈数据由prompt、模型补齐,人类对y的评分,人类对模型输出提供的事后反馈组成的元祖,按人类评分较高的输出排在前面,给模型提供反馈的优先顺序
训练过程中通过监督微调来调整模型的行为,训练数据时一个序列,模型基于历史的输出和反馈进行自我反思,生成更好的答案。训练的目标是染模型学会从过去的输出序列中自我反思,并基于反思生成更好的输出
核心在于让模型能够反思自己的输出,并从过去的经验中学习改进策略,通过模型训练时给出多个过去输出序列和对应的反馈,不仅预测当前最优的输出,也要理解过去出书的不足之处,从而在新任务中避免相同的错误。
在训练中随机遮蔽0~5%的过去ttoken,迫使模型不依赖于某些常见的词汇或模式,而是能够更广泛的学习。
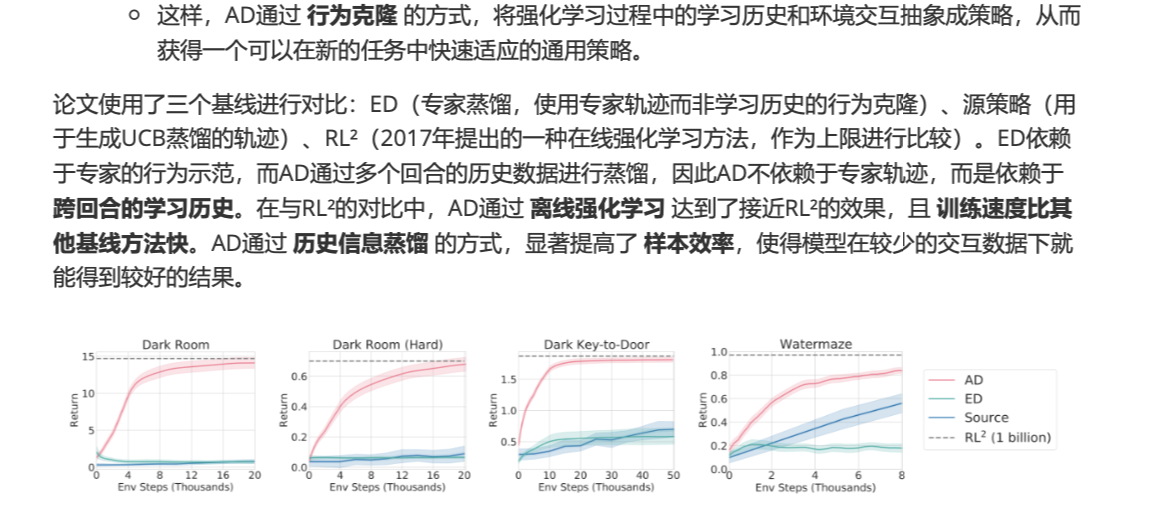
CoH的概念和算法蒸馏相似,后者应用于强化学习任务中,Algorithm Distillation 将强化学习中的学习历史提取并蒸馏成一个策略网络,通过行为克隆的方式,将Agent从过去的学习历史中获得的知识传递给模型,而不是直接训练一个任务特定的策略
- 训练过程中使用学习历史
- 训练阶段通过多个强化学习回合中收集学习历史,并将这些历史串联起来,作为模型的输入,这样可以利用整个学习过程中的经验来改进当前的决策
- 多回合历史:每个回合中的数据并不是孤立的,AD通过2-4个回合的历史数据作为输入,帮助模型从过去的学习经验中抽取规律,预测当前最优的动作。
- 目标是不再需要依赖每个特定任务的策略,而是学会一种人物五官的通用决策策略
- 强化学习的蒸馏过程
- 传统RL需要于环境交互,AD在于多个回合的历史进行蒸馏,通过行为克隆将跨回合的学习历史转化为一个神经网络模型。可直接根据过去历史做到更好的决策,而不用每次进行完全的强化学习训练
-